

Mantroid
Mantroid is a three-wheeled robotic system offering the most dexterous performance and higher payload capacity for complex assemblies. Its height adjustability and extended reach enable narrow space access for high paced logistics and retrieval tasks across varied heights.

CyNoid (7-DOF) is a mobile robotic system with three 7-axis arms, designed to handle complex tasks with greater flexibility and reach. It works efficiently in tight or changing spaces, bringing reliable, precise automation wherever it moves.

CyRo is a dual-arm, vision-guided robotic system designed to handle unknown objects and perform intricate tasks with human-like dexterity. Powered by real-time perception and force-aware manipulation, it adapts on the fly - no retraining required.


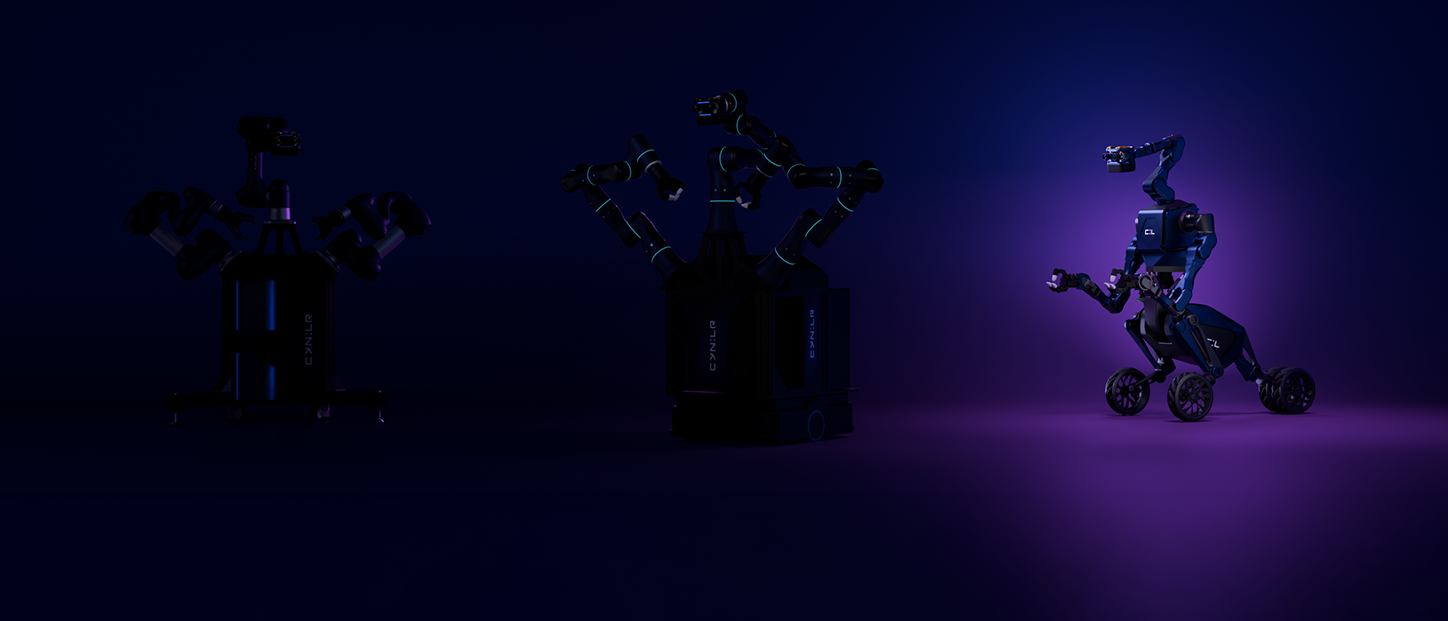

CyRo
CyNoid
Mantroid
Mantroid
Mantroid is a three-wheeled robotic system offering the most dexterous performance and higher payload capacity for complex assemblies. Its height adjustability and extended reach enable narrow space access for high paced logistics and retrieval tasks across varied heights.
One intelligence.
Infinite Tasks.
Discover how Object Intelligence allows one robot to adapt to shifting production demands with a simple software update, drastically improving parameters including Line Changeover Time, CAPEX Reusability, Overall Equipment Effectiveness, etc.
Submit your specific requirements and find your end-to-end automation solution.
Universal Factories
Imagine a future in which a single factory is capable of manufacturing multiple product models and endless product variations, the same factory makes Cars today and Mobile Phones tomorrow. This is the future of manufacturing we envision with CyRo - One Robot for all tasks. A Cluster of CyRo's working in unison to assemble a million different parts to make a million different products.
Explore the intricacies of our innovative technology and discover the endless possibilities.
Interested? To know more about CynLr
GET IN TOUCHIn the News





CLX1- Vision Stack
An Intelligence stack that instinctively sees any object in any environment, with NO training. Just like a baby's brain, this unique HW & SW Vision Platform allows building of machines that are intuitive about objects like never before - From Robots assembling parts in Factory lines to Autonomous Driver Assistance to Object Search.
WORK WITH US
"Adapts to any amount of lighting variations"

"Identifies even mirror-like reflective parts"

A camera that "sees" Motion & "feels" Force
Object Processors that learn to See and
Manipulate any Object

Grasp any object
without pre-training
Just like how humans can grasp unknown objects they have never seen before, CynLr's technology enables robots to grasp any object without any pre-training. We only learn objects after we pick them up.
Learn to manipulate
and re-orient
We identify an object by its Shape & Colour. But, when the object's orientation changes, the same object assumes different shapes and colours. Our technology allows robots to instinctively learn to put together an object from all its complex shapes and orientations and know how to re-orient them.
Make oriented
placements
One can't build a car by throwing parts at each other. We enable robots to not only grasp objects from unstructured scenarios, but learn to make oriented placements to achieve desired outcomes.
Robots deserve better than Sensor (Con) Fusion
Con Fused
Sensors
The Human eye doesn't use different sensors for Motion, Depth, and Colour.
Making the cacophony of RADAR, LIDAR & Vision Fusion Redundant. One Vision Platform To Rule Them All. CynLr's Vision system sees Motion, Depth, and Colour, all at once, in same resolution, in sync through the same pair of eyes.
Convergence
of Eyes
Ever wondered why all animals 'Converge' their eyes? Depth is perceived through Convergence.
Convergence gives 10x faster Depth at 3x the resolution than traditional stereoscopy. No more wasting compute power in calibrating the images and feature-extraction for constructing depth. A lidar and camera in one.
Create rich visual physics models of objects
'Sight' is not 'Vision'. Vision occurs when sight overlaps with all other senses, giving meaning to the colours that we see - a mango or a spoon.
Human Vision understands Objects through 7 different dimensions of information - not just colour and depth. We create rich visual physics models of objects through combination of Liquid Lens Optics, Optical Convergence, Temporal Imaging, Hierarchical Depth Mapping and Force-Correlated Visual Mapping and many such technologies.
Interested? To know more about CynLr
GET IN TOUCHPartners and Collaborators
Join a global ecosystem of innovators who are redefining intelligent vision and robotics. Collaborate with CynLr to accelerate breakthroughs, share expertise, and unlock new markets.


Team
is the Tech
Between a concept and a product lies a whole organization. A product is an outcome of interactions between several complementing minds and the ideas bouncing between them. Individuals may build a concept, but it takes an organization to build a product out of a concept.
